Anatomy of an agent
I went to a web conference this week Vancouver Web Summit and had the pleasure of meeting dozens of AI startups, some of which were workflow and automations related. But I noticed a disturbing portion of them still in the paradigm of building an agent as connecting a graph of data-passers on a no-code platform. i.e. Langchain, n8n, etc.
 |
|---|
| Fantasia (1940): the ideal agent-training interface. |
But like the no-code platforms of yesteryear, the mere abstraction of a workflow demands humans capable of understanding both the workflow and its abstraction simultaneously. We call these people developers. This is why many people believe that AI of today is a continuation of the many layers of abstraction we installed on top of assembly code. The only way that this is the final abstraction is if the users themselves are the ones that develop their automated workflows. Once this is possible, companies that promise workflow-building through their expertise will be delegated to the plumbing work that is data ingestion and output mapping.
During the days before MCPs and chain-of-thought, tool-calling and human-specified order of their execution was necessary to build a workflow. Automation of knowledge work became possible with that way of building. But now, we don’t need to specify those anymore. SOTA LLMs are now capable of calling the right tools in the right order to achieve the objective they’re given. You can see evidence of this in my very first MCP post, Midi via MCP.
Things are moving so fast, that best practices from a year or two ago are outdated. For example, using RAGs were a way to complement small context windows. Now, with Gemini supporting 2m token context windows, RAGs are rarely the right answer for most tasks. To learn more, I suggest watching this video by Devin Kearns on Youtube
What used to look like this is now obsolete:
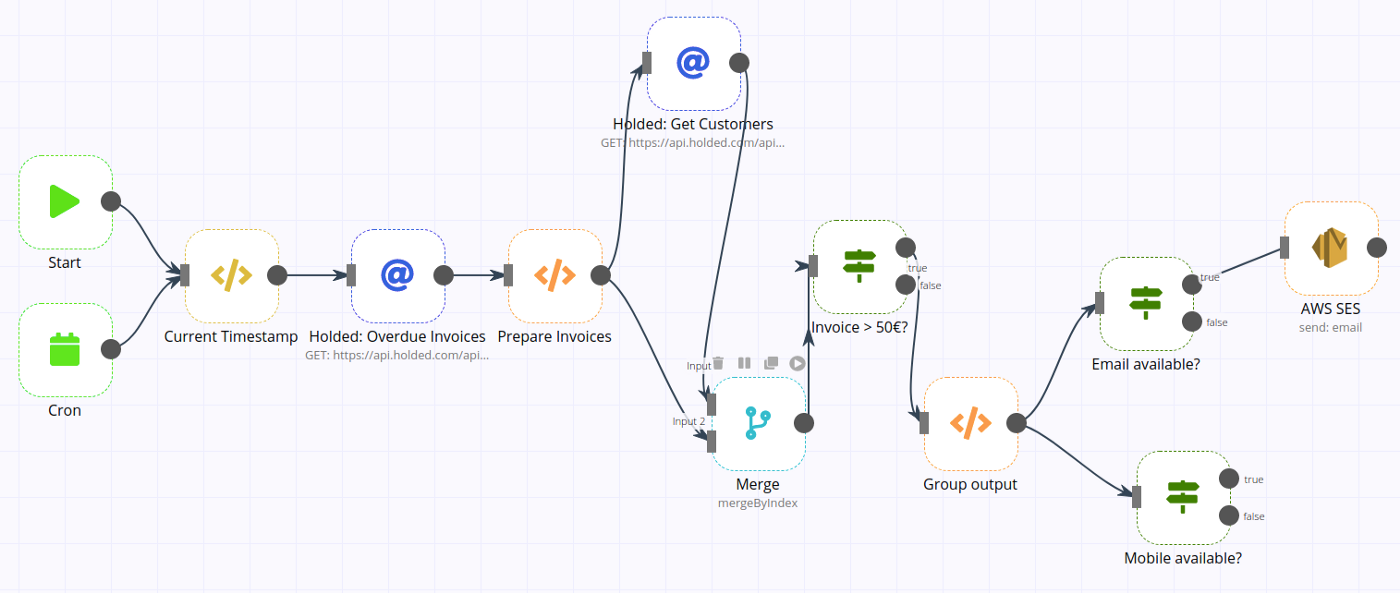
Out with the old, in with the new:
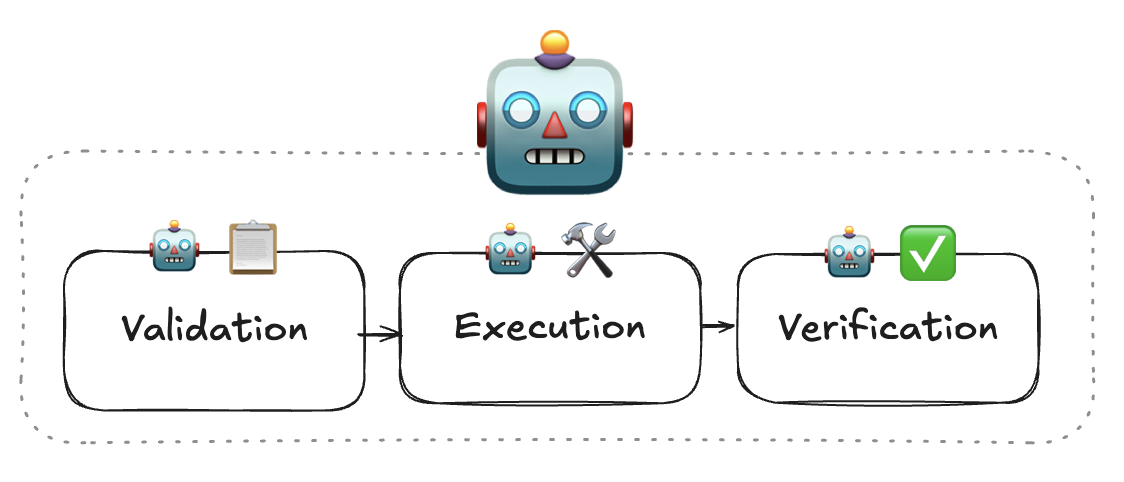
Instead of a bloated team of specialists, we only need to employ three custom prompts in a team. Optimizations such as access to a database are either configured or looked up at runtime as MCP servers. Plumbing work and front-end UI not included.
Validation
The real world is messy, and humans are even messier. This agent should be capable of taking in natural language as input, and translate it into a structured request. Like a receptionist, the validation step can include authentication, payments, and form-filling. It should be able to reject invalid or incomplete requests, and suggest missing fields. The customization to enable validation is a system prompt. With the learning agent, this can be performed by the user. Let them prime the system prompt with a description of their workflow. Then throw them a few test examples to get them closer. And during production, give them multiple suggestions to choose from, so that the system prompt can be optimized, live.
Execution
Once a request is validated, it is translated into action via a series of MCP calls. Here, the strategy isn’t to specify what explicit steps to take, but rather to give it a success criteria and let the SOTA models express their full capability. With thousands of MCP tools available, the public ones can be loaded at runtime. See MCP in the Shell for a demonstration on MCP servers being configured at runtime. By employing a RAG-MCP, a pre-execution step can be added with a fixed prompt to retrieve only the most relevant MCP servers. UI commands can be returned at this step to display the state of the request. When generative UI becomes sufficiently advanced, an entire HTML page can be rendered, removing the need for a template altogether. Until that happens, a template that can accept and send requests will be needed.
Verification
This step is for the human administrator. Verification should allow humans to inspect the performance of the agent. This could be another MCP tool call, but the execution step does not guarantee that it will be invoked every time. The executioner may time out or break, so an independent agent is needed to watch out for those errors.
Notice that the developer of this agent should not be involved with the workflow itself. The workflow should be configurable by the user, and should be optimized with use. Guardrails should also be configurable by the user in a settings menu, such as which MCP servers to allow, and the scope of what makes a valid request.
There is no messing around with what shape of data is passed between the components. It’s smart enough to send a mix of structured and unstructured data to one another.
If there is an optimistic future for AI taking over our jobs, it’s one where the employee is actively involved in training the AI to do its job. And us developers, we should be active in developing agents that doesn’t require our input after shipping it.