The Learning Agent
How does your agent improve with experience?
 |
|---|
| Feedback Controls: Britannica |
When I was thinking about implementing Prompt Builder in production, I realized that each time that the requirements changed, a developer would need to change the hard-coded system prompt that generates structured data. So if the pizza shop suddenly started supporting kimchi as a topping, that would need to go in the configuration and be checked in. Or, if cheese is no longer generic and the user has to be prompted on which kind of cheese, then that would require a developer to manually intervene and change the system prompt. Then the changes will wait until after tests and deployment to take effect.
But if you were to think about hiring a receptionist, you’d expect them to get better at their job over time. The more experience someone has, the more successful they will be, without needing to be told every time there’s a minor change. We should expect the same for our agents.
Imagine that you have an email assistant. Would you rather hire the apathetic rule-follower that never adapts, or a pragmatic learner that improves their responses based on your quick feedback? I see this mistake being made on Linkedin, among many others:
 |
|---|
| What LinkedIn thinks helping me looks like |
After listening to Koomen’s Horseless Carriages blog article as a YC podcast video on Youtube, I was inspired to do better. Instead of slapping a chatbox with a fixed prompt on top of an existing UI, the UI has to be AI-native. This means empowering each user to change the system prompt, and take ownership of it.
But system prompts are tricky. Small differences in the prompt can generate huge differences in the output, and the user shouldn’t be responsible for A/B testing a system prompt against another, as fun as that may be for some. And it shouldn’t be the developer’s job to write one system prompt for everyone, it’ll turn out bland and lifeless like the example above. That leaves the user in control, but can they be trusted?
Control doesn’t necessarily mean that they raw-dog write the system prompt. They can provide feedback against real and generated inputs, which the agent can learn from. Learning is a meta-process that considers the context of a new piece of information, evaluated against previous success metrics. And this learning algorithm can converge on a system prompt that performs better than the last in the presence of novel experience.
This might sound really complicated, but it’s actually well-studied. it’s called Reinforcement Learning. And in the context of generating system prompts, it’s called PRewrite. The paper was published in 2024, before SOTA LLMs can be trusted with qualitative evaluations of human feedback, so they used PPO instead of asking Claude which one’s probably better.
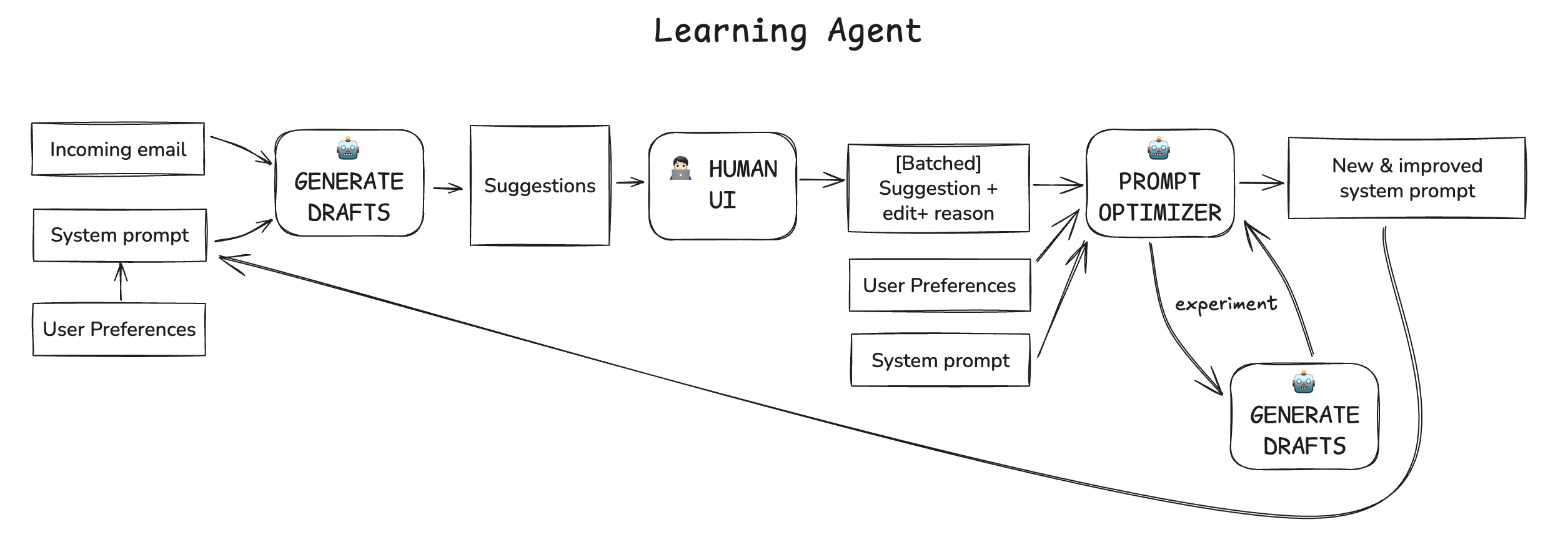
So I wrote an implementation of PRewrite, complete with UI for your curiosity. Check out LoopLearner on Github. Of course it’s coauthored by Claude Code.
I hope this post helps you think critically about what it means to allow agents to learn and adapt to the user’s needs. If you found this interesting, let’s geek out about this stuff.