Token Efficiency
Thinking about tokens is a lot like thinking about RAM and stack memory. Now that we have skills, MCP, and subagents to be able to delegate tasks, it’s the human’s job (for now), to figure out when to use which.
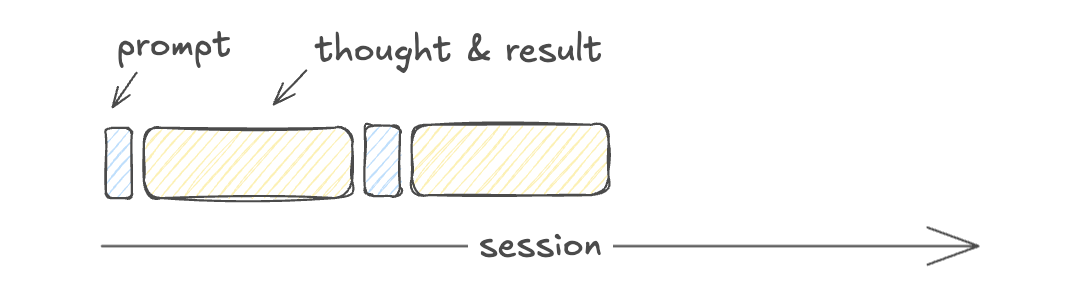
Let’s visualize how contexst accumulates. Each row of bars represents a context window.
 |
|---|
| Token accumulation thru a normal conversation |
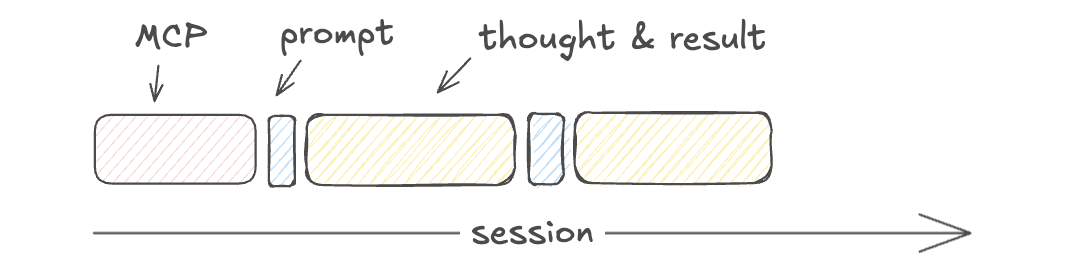
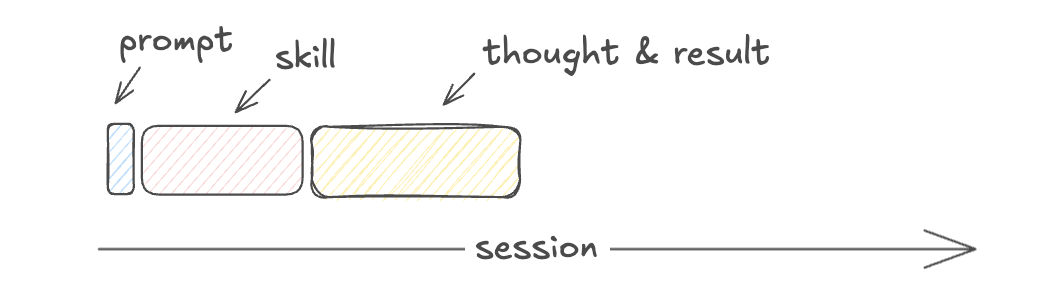
What’s the difference between MCP and skills?
 |
|---|
| MCP Servers take up a bulk of the initial context |
 |
|---|
| Skills only conditionally consumes context, on demand |
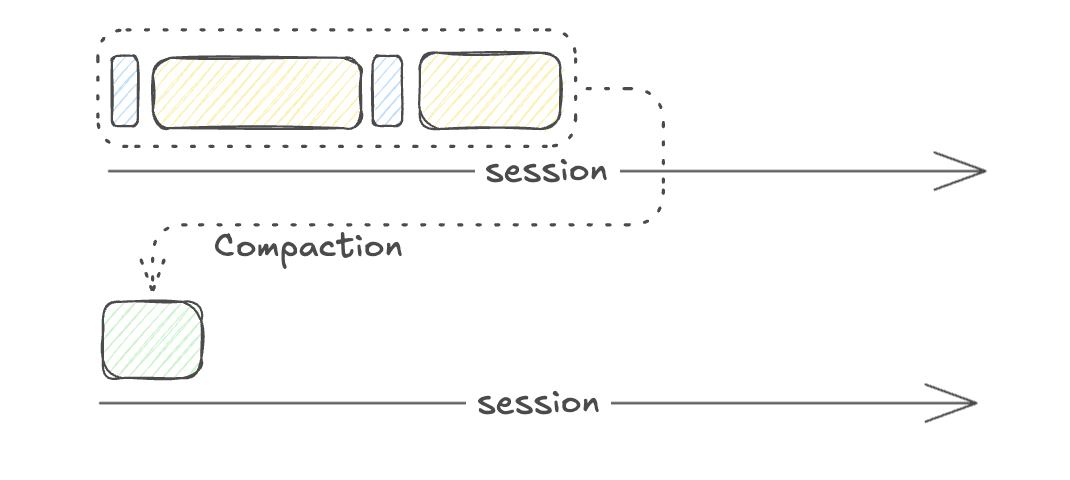
What does compacting do?
 |
|---|
| Compacting is a crude way to clean up context rot |
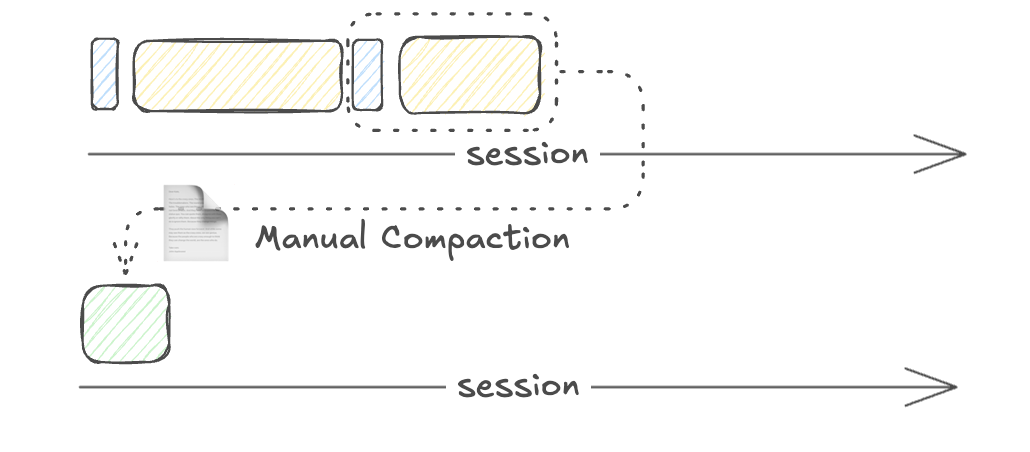 |
|---|
| Manual compaction maintains focus |
What happens if you delegate some thought to a subagent, such as research?
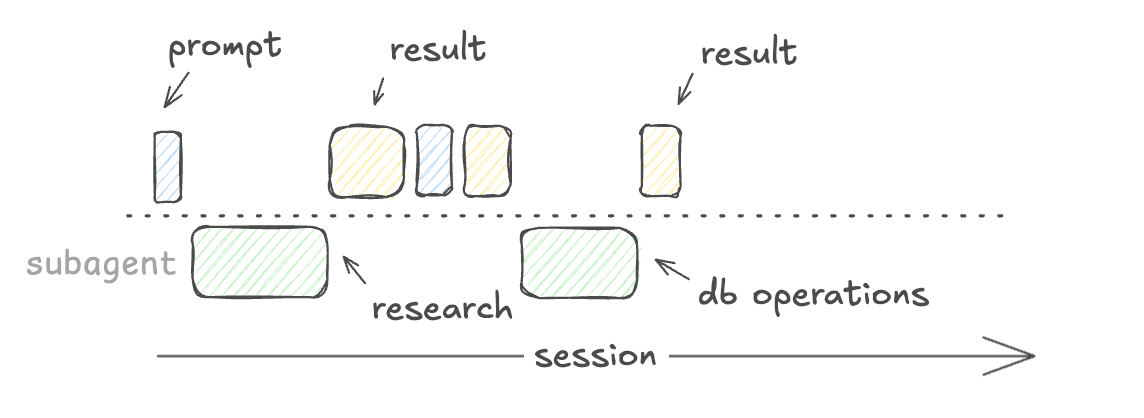 |
|---|
| Spawning subagents isn’t faster, but it prevents pollution in the main agent’s context |
By visualizing it, we immediately recognize how we can better fit the lego pieces together. If each subagent is ephemeral, and their performance depends on focused scope, then it makes sense to specialize and call them as functions as often as possible from the main agent.
This implicates a heuristic for summoning specialized subagents. When you only want the answers and none of the in-betweens, spawn a subagent.
Token efficiency is the equal and opposite optimization problem to managing context rot.
What we’re really after is the quality of results from focussed effort from our coding agents. One bad decision from the planning phase can cost more time to debug than the planning itself. This meta-cognition optimization is worthwhile for the sake of quality.