Never test in whole what you can test in parts
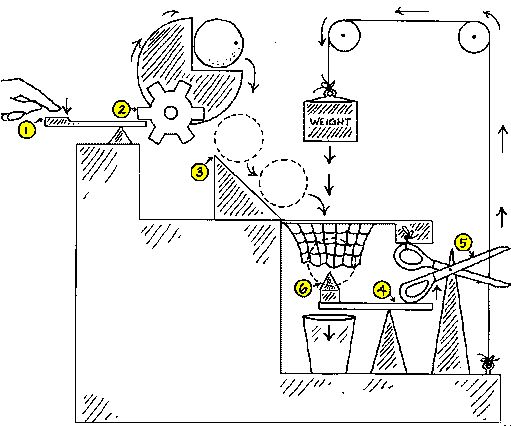 |
|---|
| A Rube Goldberg machine |
Apps can be complicated. There’s a long series of events from user request to wish fulfillment. As the app grows during development, the first intuition is to add bits and pieces and see if it keeps working. This is fine for the first few steps until one of the parts stop working and you don’t know which one.
What went wrong? If there’s only one place to initiate a test, then somebody has to go look for the fault, time taken away from being able to add new parts. As the number of pieces grow, so does the chance for one or more parts to fail.
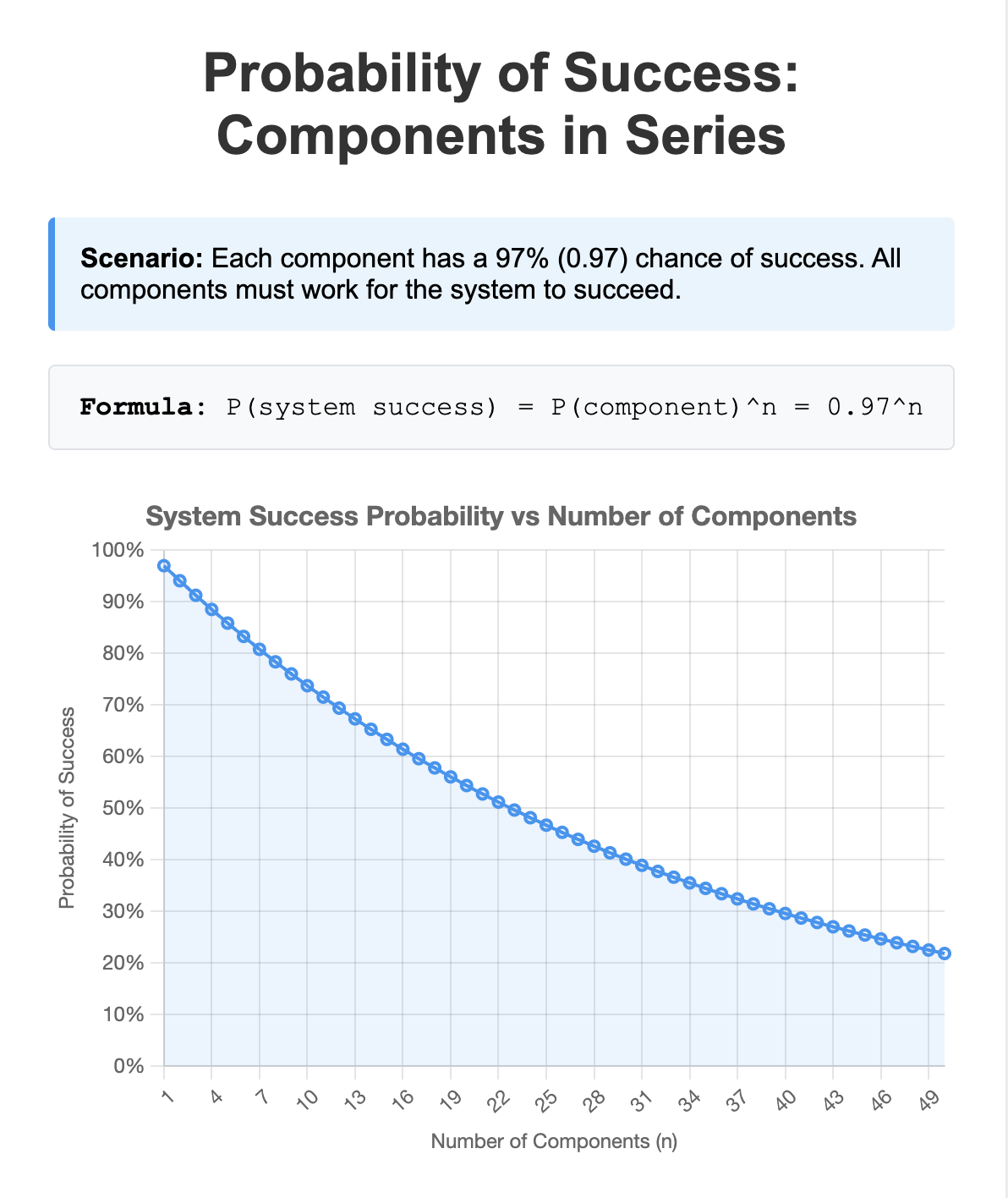
In a traditional deterministic system, this would have been tolerable for a while, as the chance for success is near-100% and not fluctuate. Using a single testing entry point would have scaled thru an entire application.
 |
|---|
| Link to Claude Artifact |
In a system that relies on nondeterministic LLM calls, development will hit the wall pretty quickly, where more time is spent on debugging existing components rather than building new ones. If regressions are tolerated, good luck finding time to add new features between debugging, meetings, migrations, planning, hiring, …
Preventing bugs in the first place is no guarantee, either. No human (or AI) can be expected to write bug-free code. Even the most basic of algorithms, binary search, had a bug in it that lasted for 9 years! See: Bug in Binary Search - Computerphile. You need to be prepared to fix the bug as soon as it’s noticed.
Automatically testing each part independently of one another cuts attribution time to an instant. It also cuts the time to fix the bug because the tests run that much quicker. And if all the parts work but the system doesn’t, then it’s an integration issue.
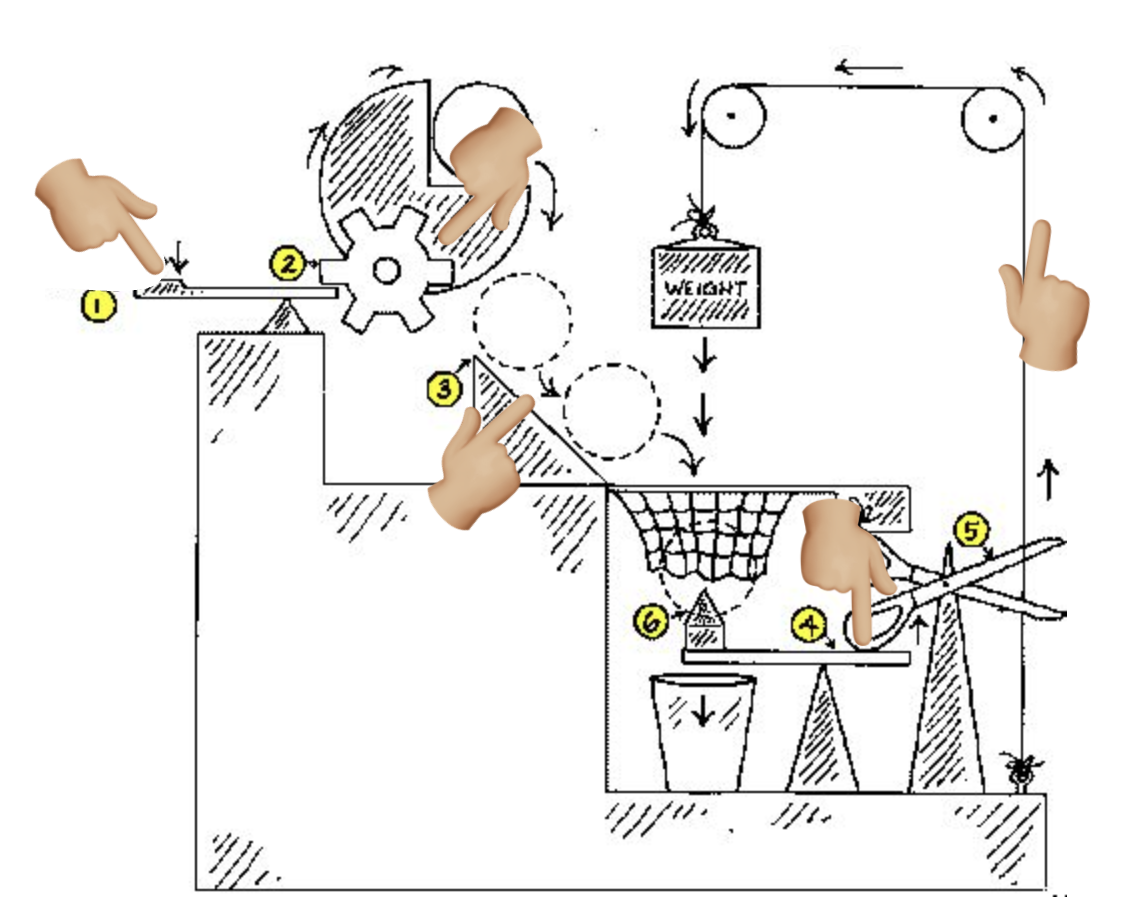
Test boundaries should be drawn for each feature delivered, to prevent regressions. Whether you write the tests before or after, isn’t as important as the discipline to have some at all in each development cycle.