MCP Browser History
In preparation of our consciousness merging wholly with the machine, I prepared an interface to which we can store our history. An implementation of a second brain came with manual annotation and note-taking management. But why can’t it just know what I’ve been up to? The computer in front of me should know what I’ve been browsing, and compute automatically on my behalf.
This is the vision illustrated dystopically in a Christmas Special episode of Black Mirror. Featuring Jon Hamm, it’s an easy recommend. Watch it if you haven’t.

The video on top of this page is demonstrating how something like this could work by using MCP servers. Instead of gluing together pieces on a backend manually, Claude (the MCP client in the demo) just knows what semantic search to trigger to fulfill my request. Without the need to maintain a client or glue code, I can focus on providing high quality data from the user’s computing session.
Technical implementation
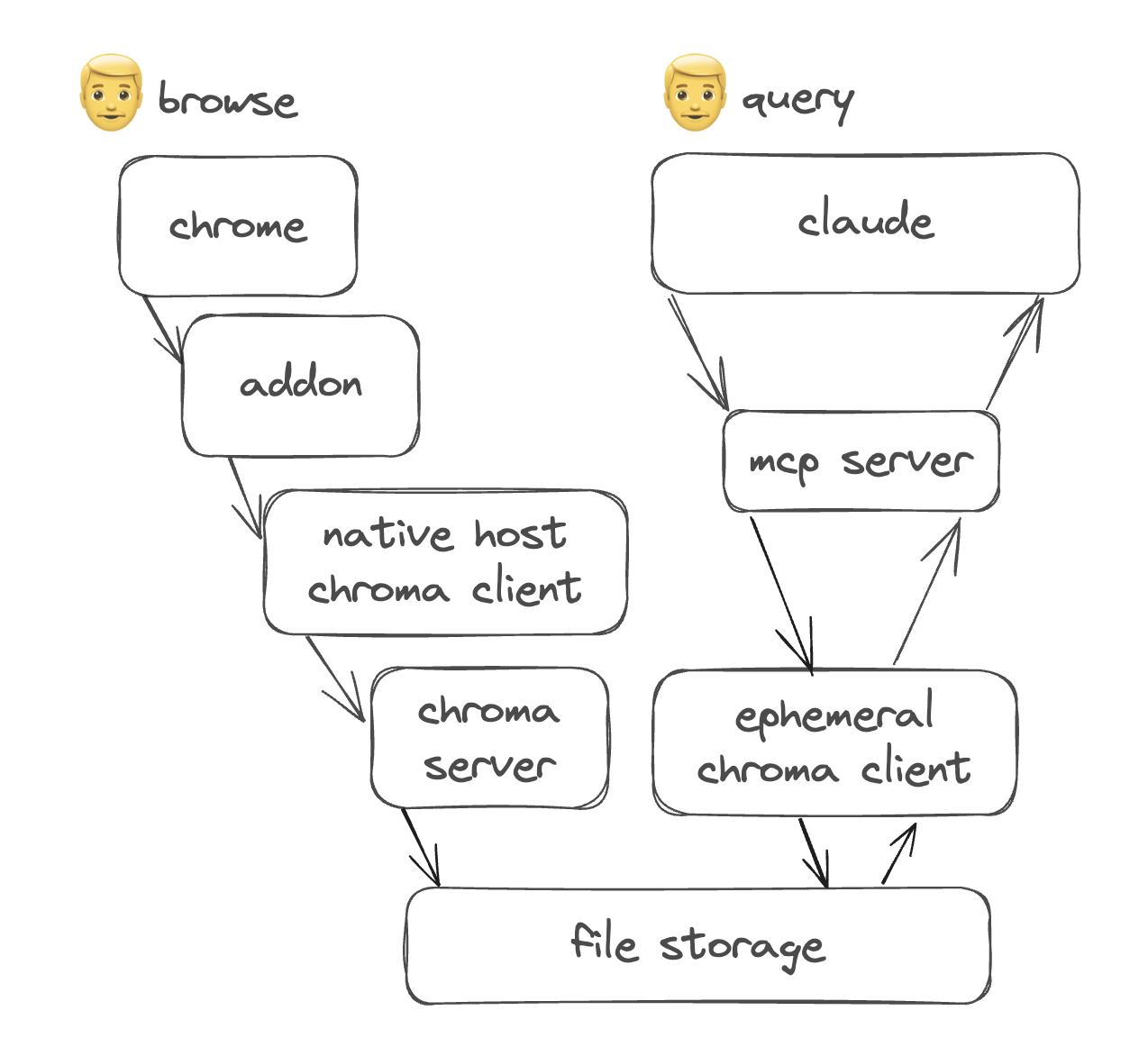
There are two main components working: the scraper and the server. The scraper is installed as a browser add-on, observing changes on screen, turning them into markdown, and saving it into the chroma db. The server is a query interface that makes it easy for MCP clients to turn natural language into tool calls. It pulls up relevant documents when invoked.
The scraper acts as an ingestion pipeline into the local db. Because Chrome add-on processes are not allowed to save files without manual user interaction, I added a native messaging bridge to a Python script (any stdio will work) that adds metadata to the markdown and saves it to ChromaDB locally. I wanted to segment each browsing session by url via collections, so there’s a semantic collection naming scheme based on the url.
The MCP server acts as a query engine for ChromaDB. It exposes methods to list collections, and to filter based on time. This allows a user to ask about remembering stuff from last week, last month, last year. It being a vector DB, semantic search and sub-second query responses from gigabytes of data is something I get for free.
There’s a couple of limitations to using Claude as a client, though. Claude has to be manually prompted to look in my history before using it, but it sometimes triggers even without it. Claude also renders the output of each memory into a textbox, which slows down the response time, even though the server has already done its job. I hope that other clients will make exposing the tool responses optional in the future.
I don’t yet have the a11y scraper installed, but that’s another module that can be built separately. Then, it can observe not just my browser, but my Slack conversations, Linear issues, and my offline notes.
If you are interested in seeing some code and the many optimizations that make it practical, see:
Browser history scraper on github
If you are working on something similar, or want to work with me, shoot me over an email.