Linkedin Scraper
Hey chatbot, can you find me a few candidates fit for this job description from linkedin?
AI Chatbots crave data. It has the world’s knowledge at its imaginary fingertips, but it doesn’t know about anything behind a login screen. Scrapers that it employed on the public web crawled the web months ago in preparation for its training. But what about live data?
If there’s a public API for it like the weather or cat pics, then MCP servers make it easy. Just hook up the API behind the tools interface and voila! But what if there’s an auth wall involved? It’s against Linkedin’s terms of service to use a robot to automatically scrape their data.
I tried using Playwright and Puppeteer MCP servers, but they didn’t allow such scraping queries to go thru. When I begged, it opened a Chrome testing window and directed me to a captcha that looked kinda like this:
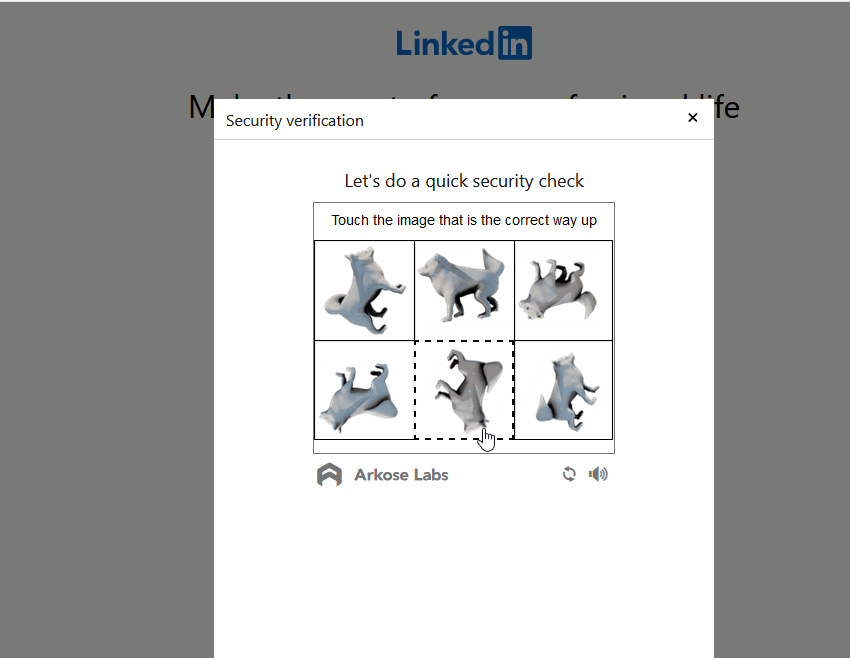
Was I going to need to capture the screen, feed it back to AI, and hope that I don’t get caught? But I already have access to the data through the front door! Why go through the back? If I can just open the page in the browser programmatically and download the contents, I can do this!
So I looked to using a browser add-on to save the data to my filesystem. But since Google’s MV3, it’s not possible to arbitrarily execute code from a browser add-on to the user’s fliesystem. Makes sense, I wouldn’t want some sketchy add-on to be able to do that. But thankfully, a side-door exists, as long as the user installs a separate application. It’s called Native Messaging.
Native messaging allows any text up to 1MB at a time to be sent over a preauthenticated bridge via stdio. The addon, upon page load, can send an async message to the background process that can relay the message to the native application.
chrome.runtime.sendMessage({
action: 'sendNativeMarkdown',
type: NativeMessageType.Content,
content: extractor.extractContent(document.body.innerHTML),
url: window.location.href,
});The native host then saves the web content (in this case, linkedin profiles) to the filesystem. Then, the mcp server that originally launched the request polls for the existence of this file every second. Once detected, the data is ingested back to the mcp client, ready for the user to consume.
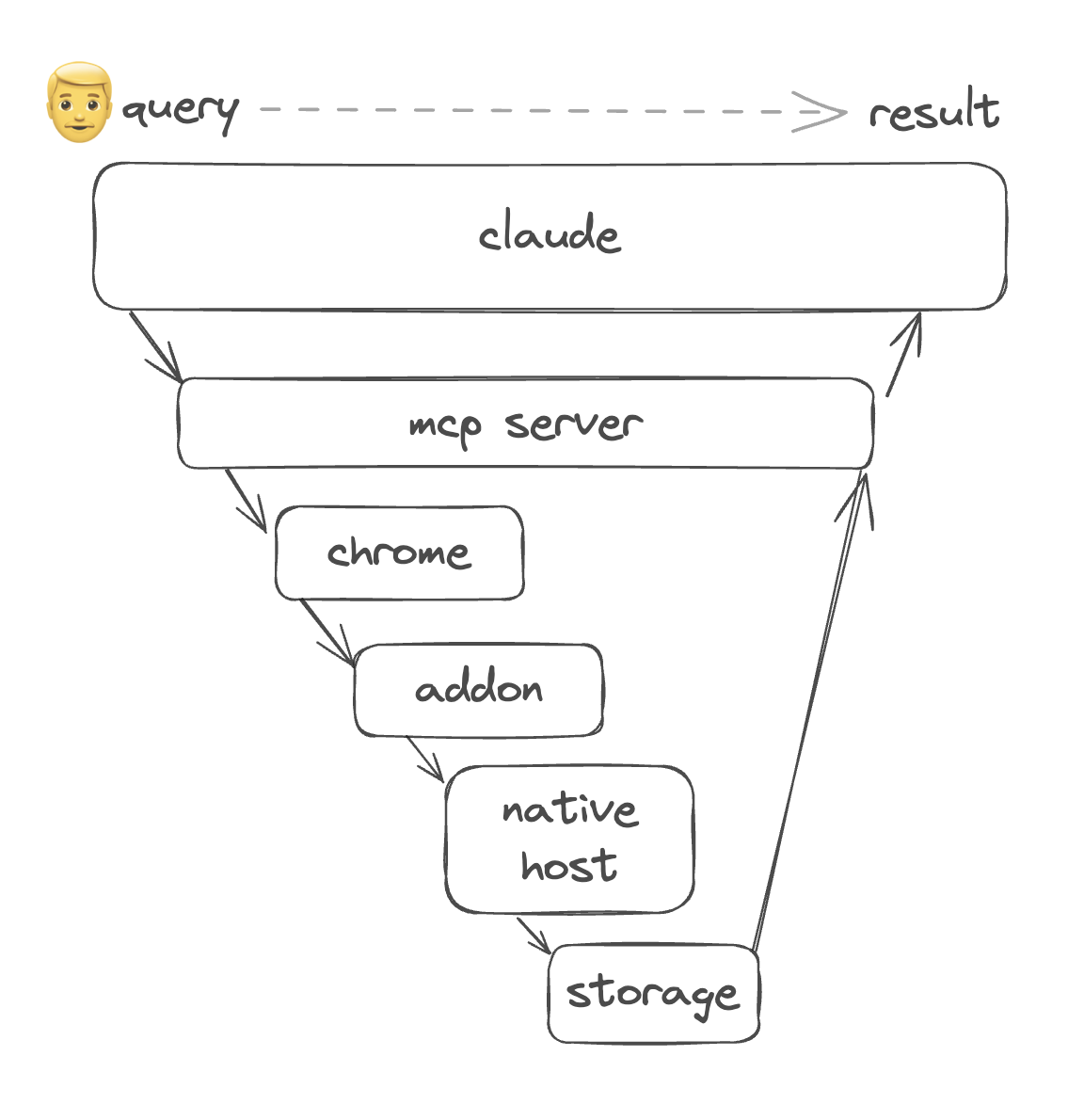
The real magic in this whole thing is how the MCP client is able to orchestrate the tool calls without explicit instruction. The MCP server only exposes the tools to the client, such as search, list, query. Any comparison operation related to natural language is handled by the client. So if I ask for people with both Python and .NET experience in Vancouver, it will come up with the search query and filter the profiles for me.
In a traditional application, such workflows would have been hard-coded and the number of workflows would have been limited by the developers’ comprehension of the use cases. Analytics and user stories would have to be concocted to close the loop.

This fundamentally shifts the role of the developer, and even the PDE organization. No GUI, no customization, no glue code. For many SaaS-like tool applications, the server-client architecture is made obsolete. The only hurdles now left are auth, packaging, security, payments.
I imagine that a collective repository of web data gathered from a large number of users will cause a network effect. The engineering challenge there would be setting up a robust vector store for fast retrieval.