Human Performance Metrics
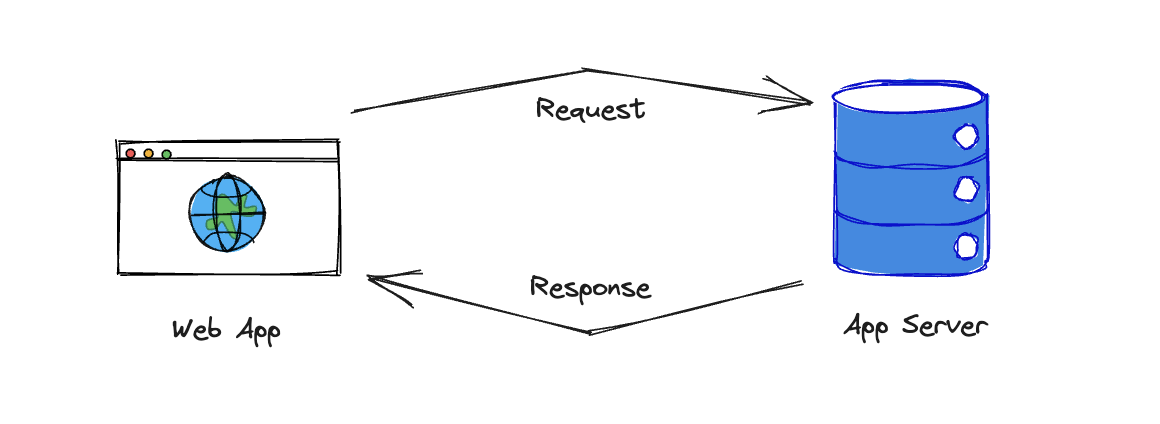
Whenever you use a web app, a server somewhere had to serve the software product through the network. We measure the performance of such servers with many metrics; such as throughput, latency, reliability, utilization are all monitored in real-time. Using multiple metrics gives its system administrators more clues about what’s wrong with the service and how to improve them. If they were to flatten it to just one number, they would be left in the dark.
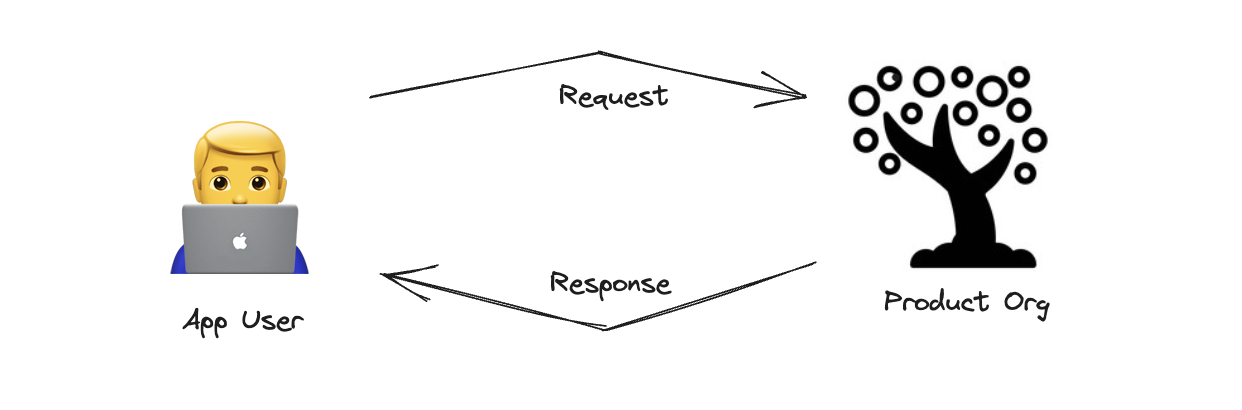
Employing structured data such as an HTTP request allows admins to employ computers to handle the task. A high-performance server would have high throughput, low latency, high reliability, and medium utilization. But when a user requests unstructured data, humans have to step in. Can you add this feature? Can you fix that bug? We do not yet have the technology to fit these requests into a standard internet protocol that a machine can handle.
Humans are needed to process unstructured requests for modifying the product. A network of humans are needed to serve such requests, and we call this network a Product Organization. Conceptually, the product organization is not much different from a web server. The only difference is structured vs. unstructured. Yet, the metrics we use for a computer made of hydrocarbons are far more primitive than the metrics used for a computer made of silicon.

Server performance is reported once every second. Organization performance is reported once each quarter.
Admins can point to a metric and refer to a checklist on how to manage it. But managers can only point to an individual’s perf and influence them.
When a server’s latency spikes up, it’s an emergency. When an organization is slow to respond, it’s not even measured.
Can us hydrocarbons borrow some management wisdom from silicon?