Filesystem Memory
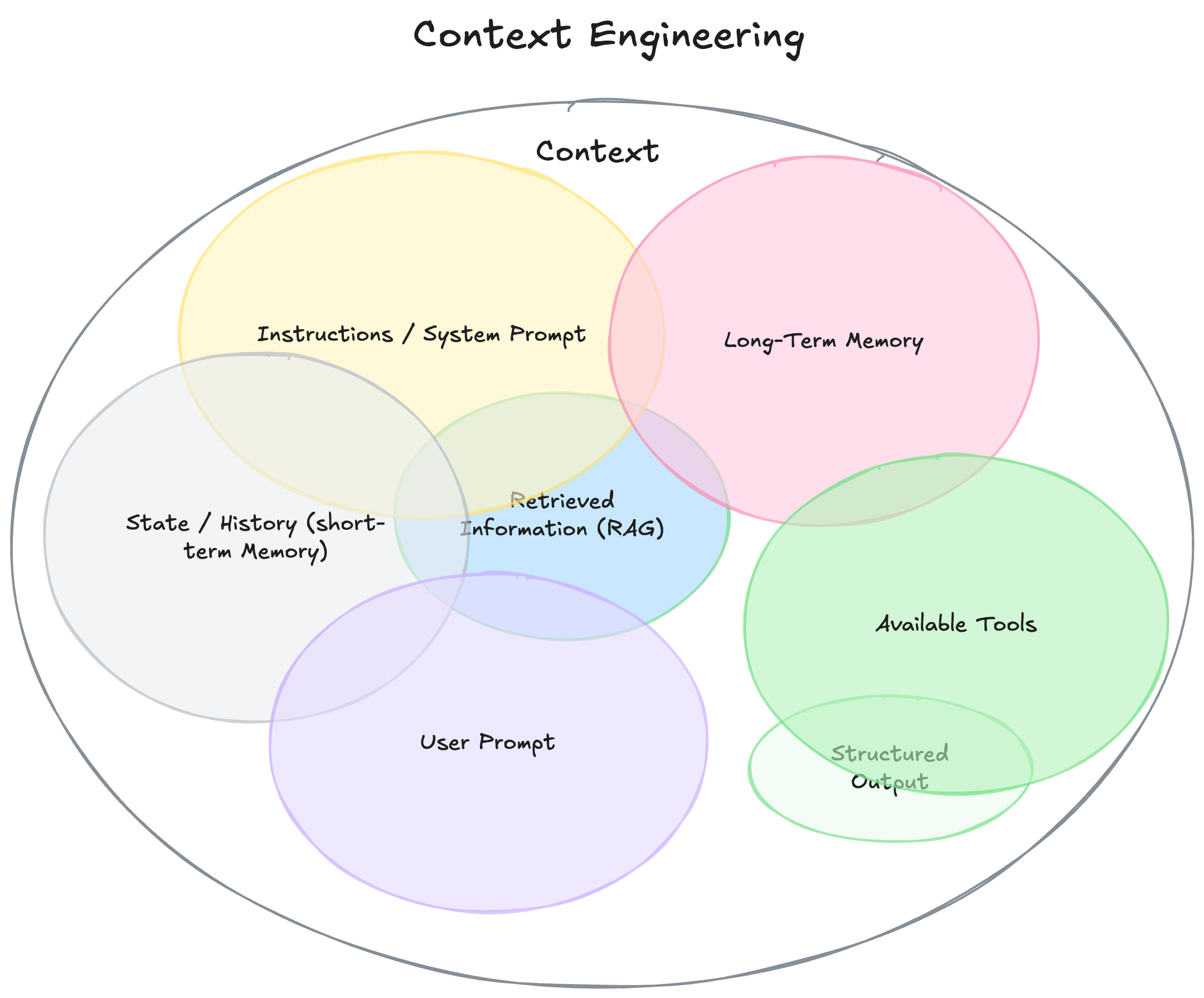
Context engineering is what they call it these days. Instead of thinking of system prompts as the main driver of LLM performance, we’re expanding the consideration to everything else involved in next-token generation. This includes peripheral knowledge around the task, including long-term memory.
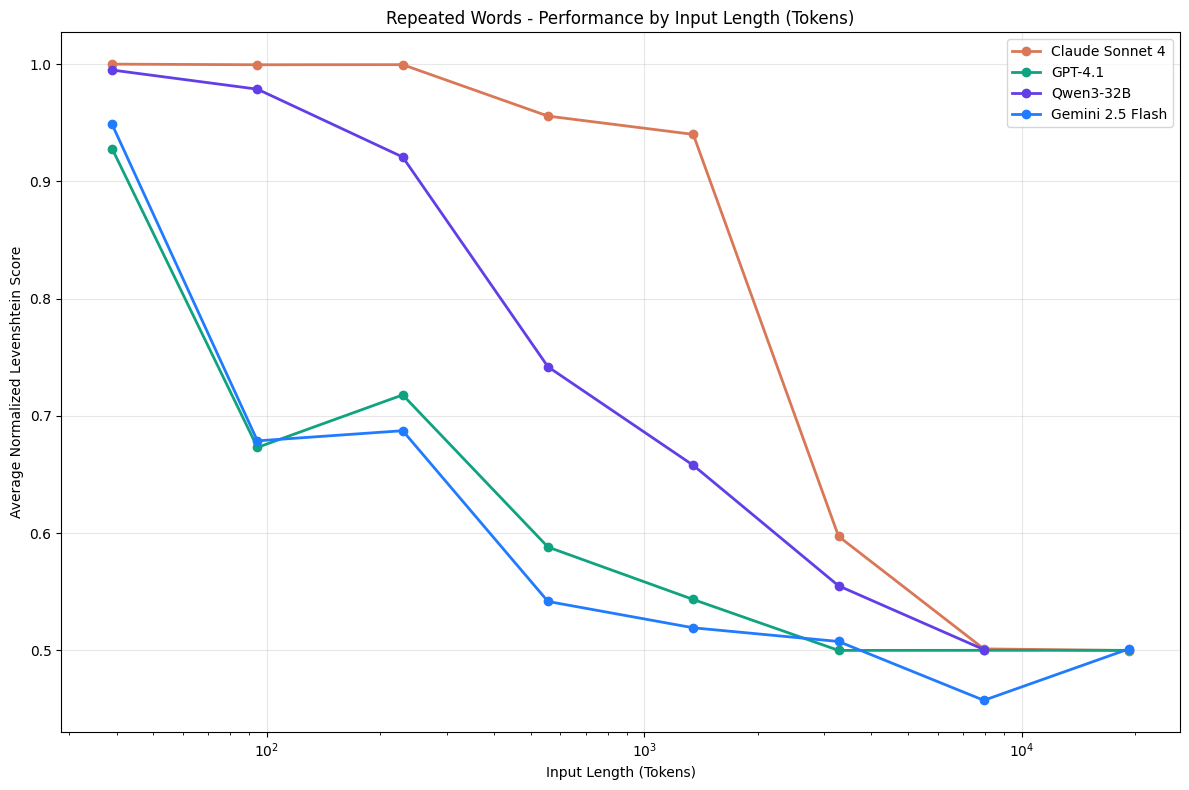 |
|---|
| Context rot degrades performance |
The default approach to memory was RAG databases up until million-token context windows made that obsolete a few weeks ago. If everything can fit into the context window, why bother with all that extra complexity? But that approach is not without baggage. Context Rot degrades task performance when too much junk is passed into context. To learn more, I recommend Chroma’s Youtube video about it.
When given an generic task, it’s tempting to put in everything into context. You can optimize performance later. But the more generic the task, the bigger the prompt gets.
This issue is obvious for MCP tool calls, where dozens of tools can eat up precious context, leading to promnpt bloat. The solution there is RAG-MCP. You can find a Langgraph implementation on Github.
Another innovation is web enablement and research. A year ago, it was a novelty; now it’s a standard chatbot feature. Public documents can be queried and valuable data extracted.
But how about data provided by the user? Large PDFs and markdowns, images and downloads? Private, potentially sensitive data that shouldn’t be stored server-side? Can we leverage the filesystem like how Claude Code can grep and find?

If you ingest the files opaquely, the user cannot remove them. If you chunk and embed them, then storage use is more than doubled. If you summarize, then details are lost. All but one approach is a compromise on data integrity. If retrieval time doesn’t need to be instant (like web search), then the files can be referenced directly.
But instead of loading all the files into every context, the files can be loaded selectively via Two-Phase Retrieval by indexing.
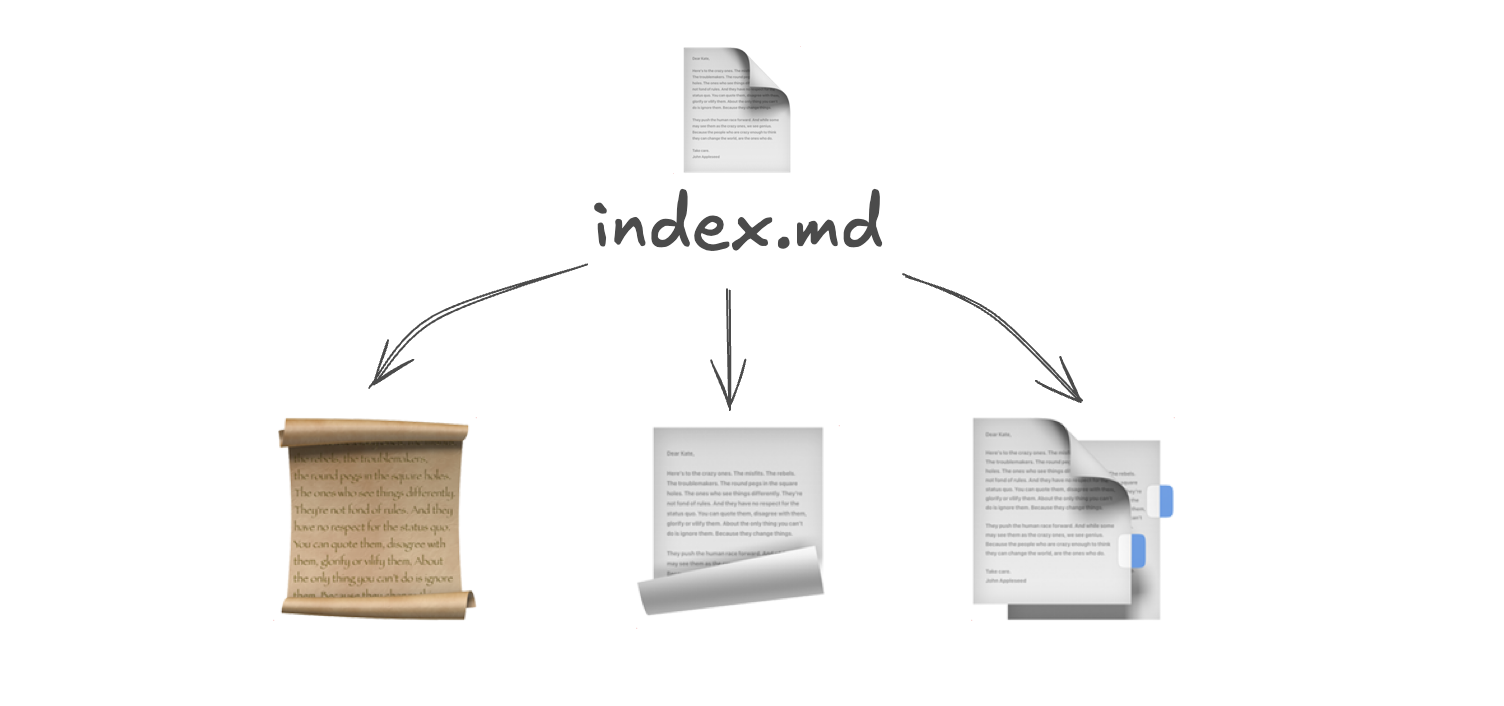
The index is a markdown file that contains the summaries of each document in the directory of interest. The summaries are generated at document insertion time, and removed when the file disappears. Summarization is an easy task, so the cheap and fast model (such as Flash) can be used. Retrieval is also powered via LLM.
To support procedural memory such as prompts, new text files or whole directories can be generated at runtime. Tha comes at the expense of additional phases, but it expands the possibility of being able to remember anything as long as it can be saved as a file.
 |
|---|
| Its biggest perk is that you don’t need to build a custom UI for context ingestion. The user can provide the files via Finder. |
One limitation is if the file is larger than can fit in a single context, then a more sophisticated retrieval method would have to be incorporated.
If the index grows to be larger than a reasonable context window, then a RAG can take its place, storing summaries and references to files as metadata.
I expect that the demand for relevant context will outpace the foundation models’ ability to counter context rot, so this should be useful for a few model releases. If you found this helpful, please reach out!
So it turns out that there’s already a startup based on this idea: Ragie, in case you don’t want to implement it yourself.