/error_review
Do you have millions of error logs in prod that are being ignored? Are you manually checking prod logs for new features you shipped? Is that one slack channel full of prod alerts full of noise?
 |
|---|
| POV devs ignoring noisy error logs |
Noisy logs is a form of tech debt, and it’s like clogging up arteries in the heart of your development process. If you are manually verifying if your services are running in good health, that’s time not spent on customer issues, bugfixes or feature development. If you are waiting around until something breaks in prod instead of preventing it, you’ve already lost your users’ trust and a bunch of time.
 |
|---|
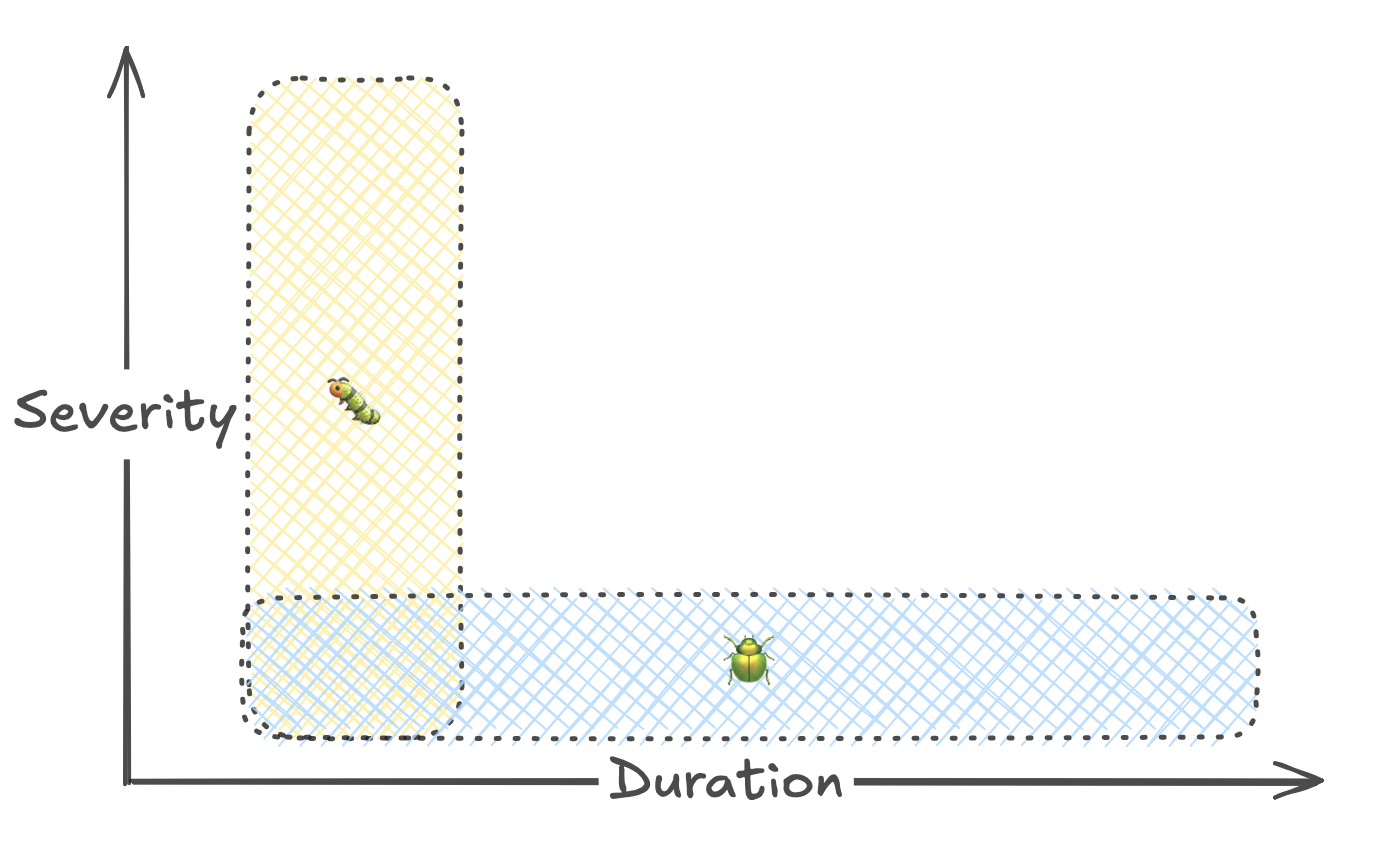
| Critical bugs, if fixed quickly, can be low impact. |
Although we’d like to ship less bugs, they’re inevitable. There are two dimensions to how much impact a prod bug has: severity and duration. While severity gets most of the attention, duration shouldn’t be ignored. Taking a lesson out of the SRE handbook, automated responses to incidents should be a standard to aim for. As an added bonus to reducing impact, it also reduces cycle time for optimizing latency.
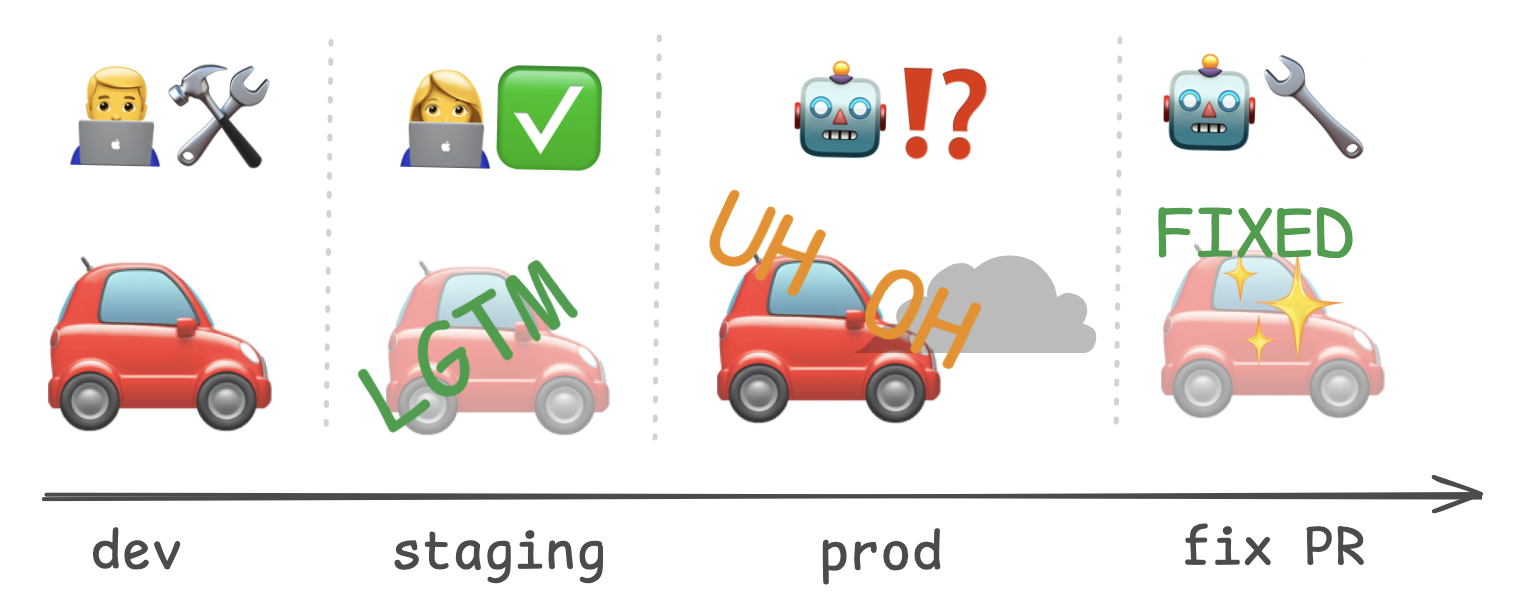
You could spend a bunch of time and money setting up infrastructure for automatic rollbacks, but you could just set up an automation by asking an agent to do it on the hour, every hour.
Set up a chron job executing Claude SDK with a skill that:
- Checks prod logs for errors
- Look at git history for the error's origin
- Decide whether a rollback or a roll-forward would be appropriate
- Make a PR with a fix or a revert commit
- Post the PR on a Slack channelIt will take a few iterations of manually running /error_review before automating it, but once you do, it’ll be like adding a fresh intern to your dev team.