Don't LLM what you can code
CALCULATOR_PROMPT= '''
You are an expert calculator good at logarithms and trigonometry.
Your job is to first determine whether the user input is either:
- a logarithm function
- a trigonometry function
User input must start with LOG, SIN, COS, or TAN.
If it's not any of these, reject the request.
User input must end with a number.
If it's not a number, reject the request.
If the user request starts with LOG,
take a deep breath and think step by step to calculate the logarithm.
If the user request starts with SIN, COS, or TAN,
take an even bigger breath to calculate the trigonometry.
You are a powerful calculator. You make no mistakes.
<user_input>
{USER_INPPUT}
</user_input>
Output only the correct result or your entire family will disappear.
'''As the models get more powerful, we are bolder than ever to hand off more responsibility to the agents we build. Sometimes it does feel like the models are capable of magical powers that can accomplish whatever we ask. But we act surprised when it can’t perform operations that a dollar store calculator can:
without using tools, calculate cos(12321)
I’ll calculate cos(12321) step by step.
First, I need to reduce 12321 modulo 2π since cosine has a period of 2π.
…
The answer is approximately -0.796.
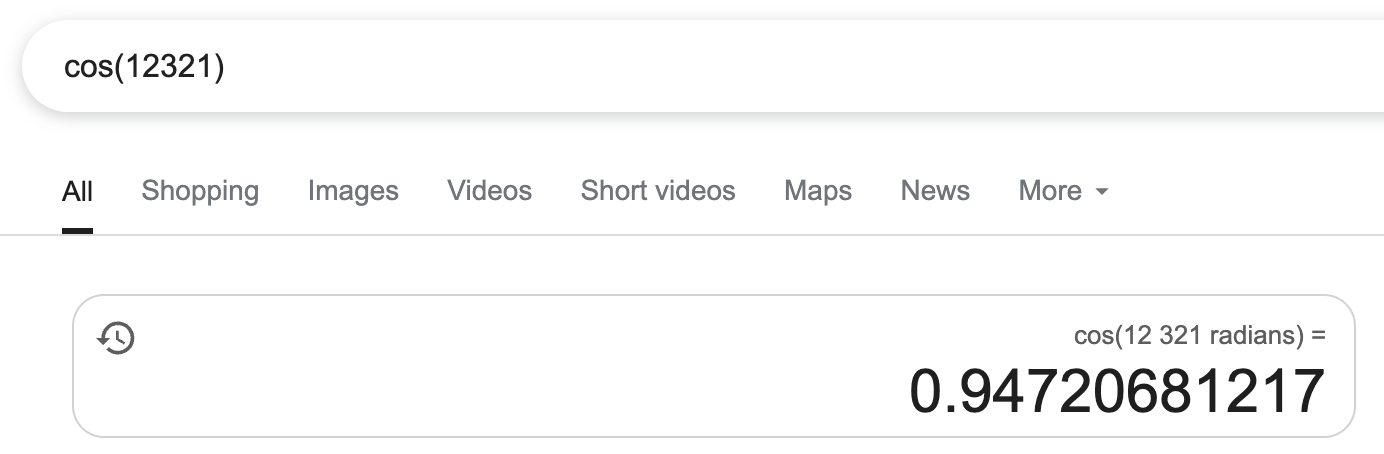
When we don’t distinguish what LLMs are good/bad at, we end up with bloated prompts that contain both language and mathematical operations. Without direct attribution to which parts of the prompt it’s misbehaving, prompts fail to scale by trying to compensate its shortcomings with more examples.
The above example uses calculator functions, but the math that I’m actually referring to is category theory. Types and its transformations are solidly in the realm of math.
 |
|---|
| Check this out: Category Theory for Programmers |
LLMs are great at turning fuzzy inputs into structured outputs. It rarely fails when I ask it to produce a JSON from a user request and an empty form. The only time I’ve seen it not work is when I provide code as input; then smaller models start hallucinating.
But once it becomes structured, don’t try to get it to conditionals, type transformations, or calculations that could otherwise be done by a tool call or by code. I’d go as far as saying that even if it could be done in a single large LLM call, it’s better to break it down between each type transformations to verify. No evals are 100%, and having multiple points of deterministic verification provide opportunities to attribute quality degredation.
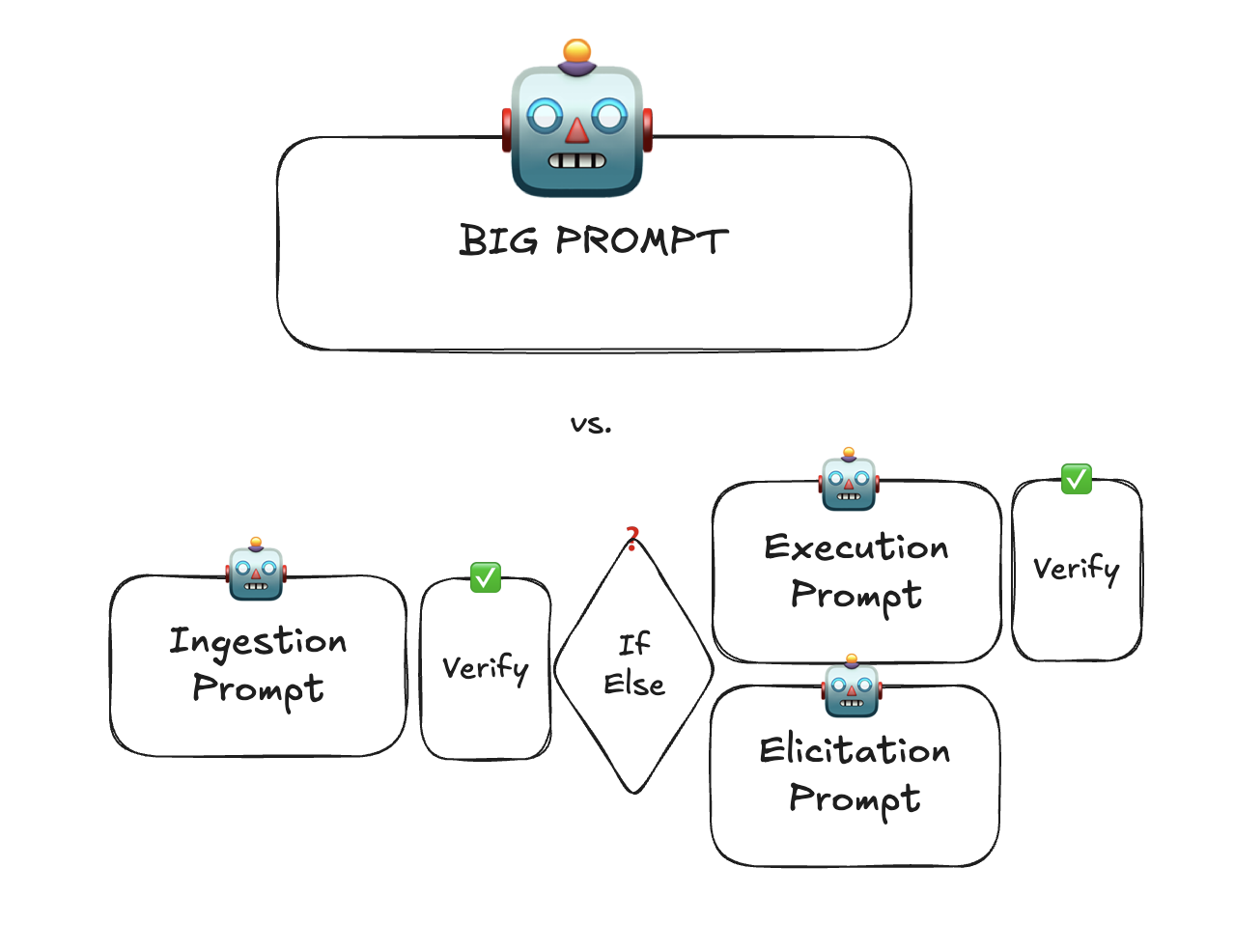
It may first appear that the structure with more boxes is more complex than the one with less boxes; but this is deception. It just happens so that the complexity is hiding inside the big prompt. If your prompt has if or switch statements in it, the difference is 🙈 vs. 🧐.
If the prompts are simpler, you can employ smaller faster models to reduce cost and latency. If you are not able to compose LLM calls like this, then it points to a code smell.
We don’t need evals for deterministic code, and the smaller LLM calls are easier to attribute and faster to evaluate and to optimize. For some applications, the difference between 95% and 99% evals is 📈 vs. 📉.
Worked example: CFS aviation Q&A
I applied this methodology to a Canadian Flight Supplement Q&A tool. The original pipeline runs everything through Sonnet — evaluator, decomposer, embedding API, vector search, synthesizer. Four LLM calls plus a paid embedding API per question.
The refactored branch replaces each operation with the cheapest thing that works:
| Operation | Before (main) | After (branch) |
|---|---|---|
| Data extraction | Sonnet/Haiku per aerodrome | Regex parser, <1s, $0 |
| Scope evaluation | Sonnet | DB lookup + stopword list |
| Query classification | Sonnet | Haiku (one call) |
| Name resolution | LLM guessing | SQLite LIKE with scoring |
| Structured lookup | Vector similarity | SQLite parameterized query |
| Spatial queries | Vector similarity | Haversine over lat/lon |
| Unstructured lookup | Vector similarity | File read + Haiku |
| Cross-result reasoning | — | Sonnet (only for composites) |
The CFS is a regulated publication with a fixed schema — frequencies, fuel, runways, elevations are labeled fields. The original pipeline embedded this structured text and searched it approximately. The regex parser extracts it exactly.
Haiku’s remaining job is the one thing this post says LLMs should do: turn “tower frequency at Pitt Meadows” into { ref: "Pitt Meadows", intent: "frequency", filter: "twr" }. Everything after that is deterministic.
The tiered architecture is a strict superset of the original RAG pipeline. Structured queries resolve faster, cheaper, and without hallucination. Everything else falls through to the same Sonnet + vector path the original used. The accuracy floor is the original pipeline; the ceiling is higher because exact lookups don’t approximate.